두두둥!
이번 시간에는 "네이버 영화 리뷰"를 가지고 긍정/부정 분류하는 딥러닝 모델을 만들어 보자!!
개인적으론 이번 실습 실제 영화 리뷰 데이터를 활용하여 하는 작업이다 보니까 젤 재밌었다
우선 데이터는 크게 2가지로 나뉜다
- 정형 데이터(숫자)
- 비정형 데이터(이미지, 문자, 음성)
숫자 데이터의 경우 바로 MLP 모델 input에 넣을 수 있지만, 비정형 데이터의 경우 컴퓨터가 해당 데이터를 읽을 수 없기 때문에 컴퓨터가 읽을 수 있는 숫자로 바꿔주는 벡터화 작업이 필요하다
이미지 데이터 전처리

이미지 데이터의 경우 이미 픽셀이라는 숫자로 이루어져 벡터화 작업 없이
MLP input에 넣기 위한 1D Flatten 작업만을 진행하면 되지만,
텍스트 데이터 전처리

text 데이터는 문자열 -> 토크나이징(쪼개기) -> 벡터(숫자로 변경) -> 벡터 단어사전 만들기 하는 작업이 필요하다
토큰화를 어떻게 하는 것이 좋을까?
한국어는 어근 뒤에 어미, 조사가 붙어 하나의 단어처럼 쓰이는 교착어 형태이다
ex) 성호가 자연어 처리 수업을 한다 -> 자립(성호, 자연어, 처리, 수업) + 의존(-가, -을, 하-, -ㄴ다)
이렇게 크게 자립 형태소와, 의존 형태소로 나눠줄 수 있다
만약 이걸 형태소 단위가 아닌, word 단위로 자른다고 생각해보자
ex) 성호가 자연어 처리 수업을 한다 -> 성호가, 자연어, 처리, 수업을, 한다
이렇게 잘라질 것이다
그렇다면 "수업을, 수업이, 수업에서, 수업은" 전부 다른 단어로 취급 될 것이며,
전부 다르게 벡터화 시킨다면 저장 메모리가 폭발할 것이다
항상 기억하자. 우리의 자원은 한정적이라는 것을..😓

형태소 단위로 토큰화를 시켜주기 위해 Konlpy라는 라이브러리를 설치해 주자 :)

영화 데이터를 보면 20만개의 데이터가 긍정 1, 부정 0 으로 labeling 되어 있는 것을 확인 할 수 있다

작업 시간 단축을 위해 2만개의 데이터로만 진행해주자 !

cuda GPU를 통해 모델 학습ㅇ르 더 빨리 하기 위해 device를 설정해주고,
konlpy에서 Okt라는 형태소 단위로 토큰화를 하는 인스턴스를 불러왔다
형태소 단위의 토큰화

text라는 변수에 문장을 받아,
text가 str(문자열)이 아니거나, "or not text.strip()" 공백만 있으면
[] 처럼 빈 리스트로 반환해주고,
그게 아니면(정상적으로 통과되면), text를 morphs(형태소) 단위로 토큰화 해주자

문자열을 주어졌을때 이런식으로 토큰화 된 것을 확인하였다
현재 morphs는 단어의 형태를 유지하면서 토큰화 하기 때문에, "했다, 한다, 함, 했음"으로 토큰화가 되었지만,
morphs에 stem = True 라는 파라미터를 넣어주면

"하다"라고 통일되게 토큰화 된 것을 확인할 수 있다

원본 데이터 'document' 에 대해서 preprocess 함수를 사용하여 모든 데이터를 토큰화 해주고 'tokens'라는 칼럼에 저장한다
그리고 토큰화 한 데이터를 ' '(공백 문자)를 기준으로 합쳐준다
-> 기껏 토큰화 시켰는데 왜 다시 join해 줄까?
우리는 뒤에서 TF, TF-IDF 벡터화를 해줄건데 이 라이브러리의 경우 형태소 단위가 아니라, 공백을 기준으로 잘라 버린다.
그러니 "형태소 토큰화 유지 + 벡터화"를 하기 위해 join해 주는 것이다

TF(Term Frequency, 단어의 빈도)
한 문서 내에서 특정 단어가 얼마나 자주 등장하는지
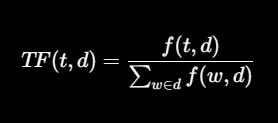
- : 단어(term)
- d: 문서(document)
- f(t,d): 문서 에서 단어 가 등장한 횟수
IDF(Inverse Document Frequency)
전체 문서 집합에서 특정 단어가 얼마나 희귀한지

- df(t) : 단어 t를 포함하는 문서 수
- N : 전체 문서 수
TF - IDF(Term Frequency - Inverse Document Frequency)
문서 내에서는 자주 나오고(TF↑),
전체 문서에서는 드물게 나오는(IDF↑)
단어에 높은 점수를 부여

- tf(t, d) : 문서 d안에서 단어 t가 등장한 횟수
- df(t) : 단어 t를 포함하는 문서 수
- N : 전체 문서 수

- VOCAB_SIZE = 5000 : 벡터 단어를 담을 단어장의 최대 크기를 5000개라고 지정
- min_df = 3 : 최소 3번 이상 언급된 것만 벡터 단어사전에 남도록
- ngram_range=(1,2) :
"재미 없다", "안 좋다" 와 같이 단어가 떨어져 있음으로 인해 단어가 외곡 되거나, 의미가 안 잡히는 문제를 없애기 위해
2단어를 합쳐서 벡터화 시킴!
('기존 형태소 토큰한 단어" + "2개를 합친 n-gram" 모두 벡터화 시키기)
예시 (문장: "이 영화 정말 재미 없다")
1 unigram 이, 영화, 정말, 재미, 없다 2 bigram 이 영화, 영화 정말, 정말 재미, 재미 없다 ← 부정 의미 살아남 3 trigram 이 영화 정말, 영화 정말 재미, 정말 재미 없다
VOCAB_SIZE = 5000개를 어떻게 맞출 것인가?
-> 가장 많이 언급된 단어를 갖고 상위 5000개만을 남기기

TF : CountVectorize(**COMMON_KW)
TF-IDF : TfidfVectorize( **COMMON_KW )
둘다 위에서 만든 **COMMON_KW(고정 최대 크기 지정 + ngram)을 적용하고 있음
- 학습에선 fit_transform(X_train_text) : 16000개의 리뷰 데이터를 흝으면서 가장 많이 나온 단어 5000개 선정 및 벡터화 + TF or TF-IDF
- 테스트에선 transform(X_test_text) : 새로운 리뷰 데이터를 통해서 넣어서 TF or TF-IDF
X shape : 16000(train data 리뷰 문서 개수) X 5000(5000개의 벡터 사전)
가장 많이 언급된 5000개 단어 사전

사전을 보면 반복적으로 언급되는 텍스트가 있는 것을 볼 수 있다
첫번째 리뷰 데이터에 대한 TF, IDF, TF-IDF
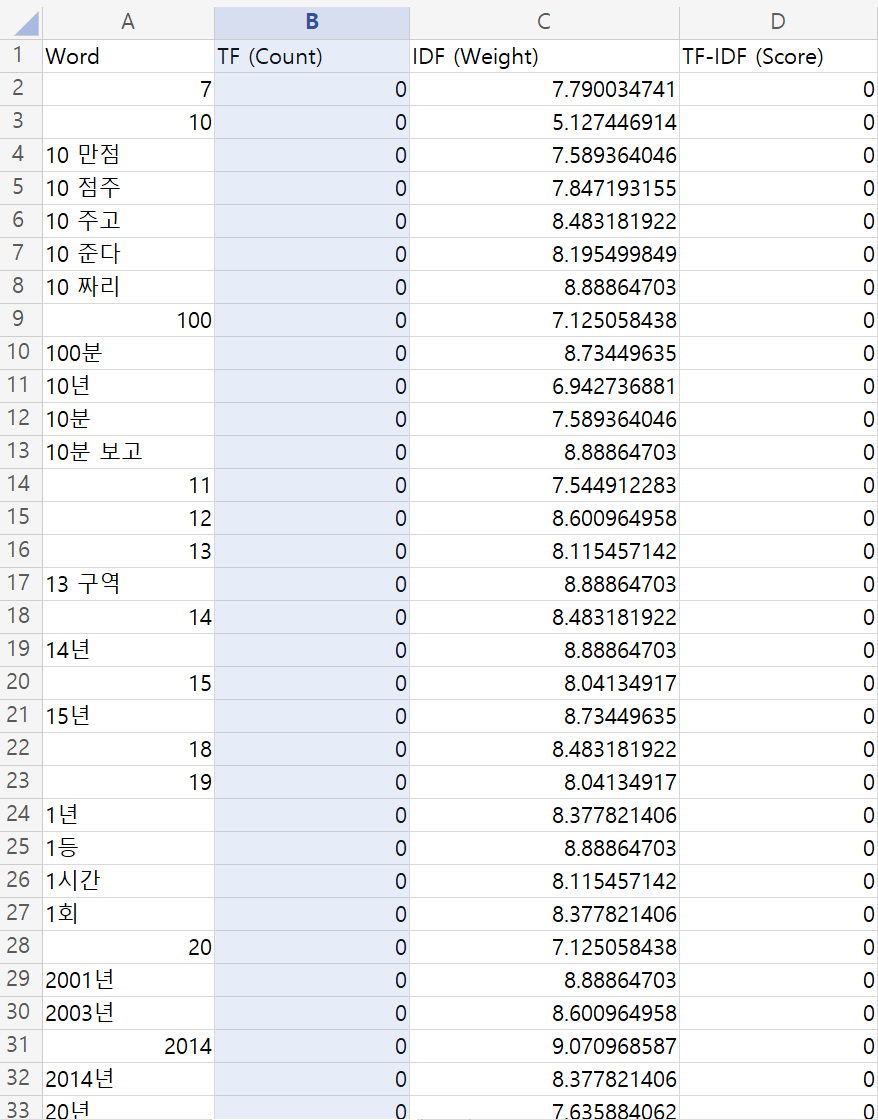

첫번째 리뷰 문서에서 농구라는 단어가 한 번 언급되었단 것을 볼 수 있다. 회소성에 따른 TF-IDF 값이 높게 설정 되었다는 것을 알 수 있다
MLP 학습 및 평가

MLP 기본 구조를 다른 것과 같이 짜주되, input_dim의 사이즈는 벡터 사전의 사이즈 5000이다(리뷰 한 문서당 들어갈 x의 길이)
CrossEntropy를 사용하여 긍정 리뷰(1), 부정 리뷰(0)을 분류하고 2개의 num_classes에서 logits 값을 출력하도록 설정해준다.

y 데이터의 경우 클래스의 인덱스를 나타내기 때문에 long 타입으로 설정해 준다
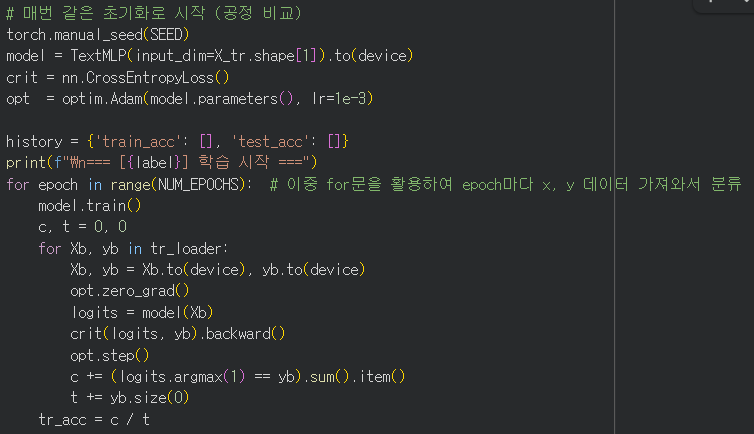
model 부분을 .to(device)를 통해서 GPU로 가속화 시켜주고, 배치로 묶은 x와 y값 또한 .to(device)를 해준다

torch.no_grad를 제외하고는 학습과 비슷하다


신기하게도 TF에서 더 좋은 성능을 보였다
리뷰 같은 경우에는 "재밌다. 추천한다"와 같이 비슷한 단어를 많은 사람들이 쓰게 되는데 TF-IDF가 중복 추천된 단어의 가중치를 낮췄기 때문에 이러한 결과가 나온 것 같다고 추측된다
또한 ngram을 통해서 단어의 의미를 합치긴 했지만, 원본 형태소 또한 학습하는 데 사용이 되었으므로,
"재미 없다" 와 "재미" 가 동시에 학습이 되어 의미 충돌이 발생했을 가능성도 있다
